I’m very happy and quite proud to announce the successful deployment of erchef on Hosted Chef this week. Getting erchef into Hosted Chef has been a long and challenging project involving a good chunk of Opscode’s engineers. Since the successful cut over to erchef, our Hosted Chef customers have seen marked reductions in API timeouts and substantial improvements in API response time.
## Fewer errors, faster responses, less CPU ##
Continuing to scale Hosted Chef to deal with increasing demand has been a serious and ongoing challenge for some months. We believed that erchef, our new API server, and Postgres would address our scaling issues. As with any serious architectural change, building and deploying erchef has taken longer than we expected.
Our scaling pain was most evident as API calls timed out and failed. For external users these timeouts surfaced as 5xx HTTP errors served from our Hosted API to chef-client, management console, and knife.
This graph demonstrates the relative reduction in 5xx errors as erchef was deployed.
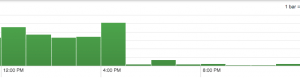
The drop off coincided with a first wave of org migrations composed of the largest and busiest customers. The drop in the over-capacity error rate was dramatic and platform wide. Moving a relatively small set of high traffic orgs onto the new system provided an order of magnitude system-wide improvement in error rate for both the new and old systems.
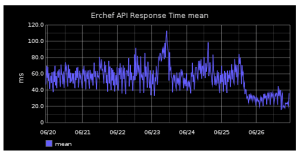
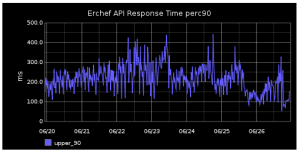
Response times have also improved. Below are graphs showing the mean and perc90 response times for the erchef service in Hosted Chef. The drop in average response time corresponds to completion of bulk org migration.
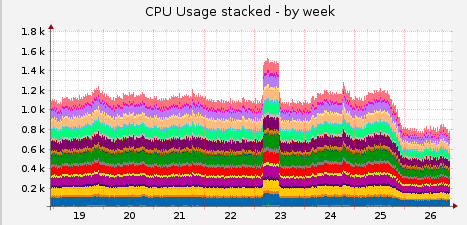
Our front end servers where we collocate the Ruby Chef Server and erchef services have seen a marked reduction in CPU use as a result of moving the traffic off of the Ruby based Chef Server and onto the Erlang based erchef.
## The Migrating Org: Don’t blink ##
Each org went through three phases during its migration. First, the org was put into “maintenance mode” such that all API requests immediately returned a 503 from our external load balancers. Then the migration tooling copied data from CouchDB into PostgreSQL. Once the data was copied, the routing rules were updated to take the org out of maintenance mode and point the org at the Erchef service.
A good migration is one that goes unnoticed. The average outage window for an org was less than six seconds. The migration time for all but one of our largest orgs fell within the retry window for chef-client such that a converge started before the org migrated would encounter some retries and then successfully complete against the new system. If you were one of 16 orgs in a single unlucky migration batch, you saw nine minutes of downtime (sorry about that). Otherwise, we suspect you didn’t notice when we moved all of your data to a new database and switched your org over to the new API service.
No migration is ever 100% perfect but overall we’re very happy with the results.

